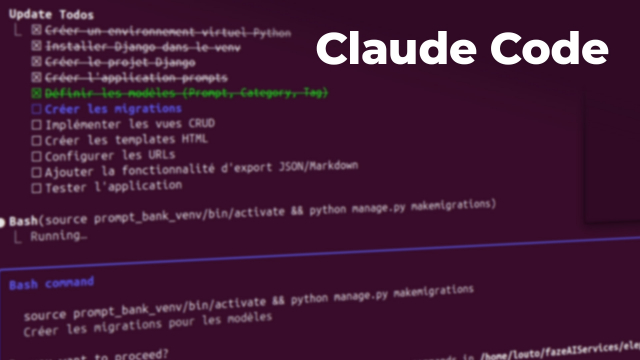
Comprendre Claude Code en profondeur



Prise en main de l'outil



Utiliser Claude Code dans votre workflow

Cas pratiques et productivité


Aller plus loin avec Claude Code


Détails de la leçon
Description de la leçon
Dans cette vidéo, nous examinons divers modèles d'intelligence artificielle utilisés dans le développement logiciel. Nous utilisons le SWE Bench, un benchmark open source créé par Princeton, pour comparer la performance des modèles tels que Cloud Sonnet 4, GPT-5, et Quen 3 Coder. Le SWE Bench évalue la capacité d'un modèle à résoudre des tâches complètes en termes de correction de code, architecture logicielle et productivité.
Nous explorons également comment ces modèles sont utilisés dans différents contextes, comme le marketing, et quelle est leur adoption récente selon les tableaux de classement d'openrouter.ai.
Les résultats montrent que, bien que Cloud Sonnet 4 soit couramment utilisé, Quen 3 Coder connaît une croissance notable. L'analyse approfondie de ces modèles aide à choisir le bon outil pour vos besoins spécifiques, que ce soit pour des projets volumineux ou pour des besoins de débogage rapide.
Objectifs de cette leçon
L'objectif de cette vidéo est de comparer l'efficacité des modèles d'IA en génie logiciel pour aider à choisir le meilleur modèle en fonction des besoins spécifiques et des domaines d'application.
Prérequis pour cette leçon
Il est recommandé d'avoir une connaissance de base en développement logiciel et une compréhension des modèles d'intelligence artificielle.
Métiers concernés
Les ingénieurs logiciels, les analystes de données et les spécialistes en IA sont parmi les professionnels qui bénéficieraient le plus de cette comparaison des modèles d'IA.
Alternatives et ressources
Les alternatives aux modèles discutés incluent d'autres outils d'IA comme TensorFlow et PyTorch pour développement personnalisé.
Questions & Réponses