Le Data Scientist intervient lorsque l’entreprise dispose de données exploitables et cherche à en tirer une décision ou une automatisation à forte valeur. La mission commence par la clarification du besoin : réduire le taux de churn, améliorer la prévision de ventes, détecter des anomalies, classer des documents, recommander un produit. Cette étape transforme un objectif métier en une cible mesurable (par exemple : gain de précision, réduction du temps de traitement, baisse d’un coût, amélioration d’un taux de conversion).
La phase d’exploration vérifie la faisabilité : qualité des champs, volumétrie, granularité temporelle, biais de collecte, fuites de données. Viennent ensuite l’ingénierie des variables, l’entraînement de modèles et la comparaison de baselines. L’objectif n’est pas uniquement d’obtenir un score, mais de fournir un modèle compréhensible, stable et actionnable, avec des hypothèses explicites.
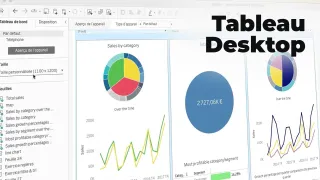
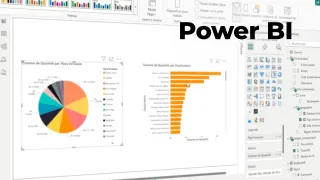
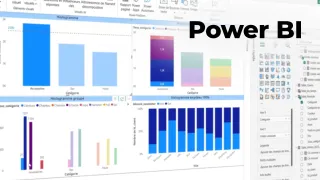
Les livrables prennent plusieurs formes : notebook d’analyse, pipeline de préparation, modèle packagé, API de scoring, rapport d’évaluation, recommandations de collecte de données, documentation pour les équipes opérationnelles. Dans une entreprise comme Doctolib, un projet typique consiste à aider à prioriser des actions ou à améliorer une expérience utilisateur, à condition de cadrer la conformité et le contrôle de dérives. Dans le secteur public, l’Insee illustre un usage adjacent : produire des analyses statistiques robustes et auditables, avec une forte discipline méthodologique.
Les missions incluent enfin une dimension de gouvernance : respect du RGPD, minimisation des données, explicabilité selon le contexte, et prise en compte des risques d’erreur ou de discrimination algorithmique.