
L’intelligence artificielle… un vaste sujet qui gagne ces dernières années, du terrain. Pas un moment ne passe sans avoir une information à ce sujet. Elle cristallise tant les plus folles aspirations qu’elle soulève de nombreux questionnements, souvent par méconnaissance quant à son fonctionnement aujourd’hui.
D’Isaac Asimov, l’écrivain et inventeur du terme Robotique et de ces lois éponymes jusqu’à Terminator ou encore Matrix, l’intelligence artificielle (IA) suscite à la fois un intérêt grandissant et des peurs. Comme toutes « nouvelles » technologies, tout dépend de l’usage qu’il en est fait, de sa finalité. Aujourd’hui, les algorithmes peuplent notre monde, s’invitent dans notre quotidien, une tendance de fond accélérée par l’essor du numérique. Et pourtant, cette technologie ne date pas d’hier ! Des premiers essais du mathématicien et cryptologue britannique, Alan Turing à l’IA AlphaGo de Google, il y a tout un monde. Comprendre son fonctionnement, c’est pénétré dans un autre univers où les algorithmes sont rois et les formules mathématiques reines.
Une brève définition de l’IA
Issues de plus de 70 ans de travaux, l’intelligence artificielle a vu sa définition évoluée. Autrefois, une boîte de vitesse automatique était considérée comme de l’IA, ce qui pour la plupart des personnes, ne l’ait plus aujourd’hui. L’une des définitions que l’on peut apporter actuellement, c’est le degré le plus élevé de résolution de tâches complexes que nous sommes capables d’adresser.
Du machine learning au deep learning
En intelligence artificielle, on distingue deux grands mouvements complémentaires :
- Le machine learning.
- Le deep learning.
Le premier cas est à la source de l’IA. Tandis qu’Alan Turing et d’autres chercheurs élaboraient les bases d’un système apprenant, le psychologue américain Franck Rosenblatt travaillant au sein du Cornell Aeronautical Laboratary, pose les bases de ce qu’allait devenir le machine learning. S’imprégnant des théories cognitives de Friedrich Hayek et Donald Hebb, il conçoit, en 1957, un algorithme d’apprentissage supervisé s’inspirant du réseau neuronal humain : le Perceptron.
Son fonctionnement se compose de quatre éléments distincts :
- Des entrées : c’est là que l’on va mettre les données (une image, des informations textuelles, etc.) ;
- Des poids : en clair, les paramètres de configuration du modèle IA afin de pouvoir l’ajuster si besoin ;
- Une fonction d’activation : elle consiste généralement en une formule mathématique non linéaire ;
- D’une sortie : permettant de donner le résultat final.
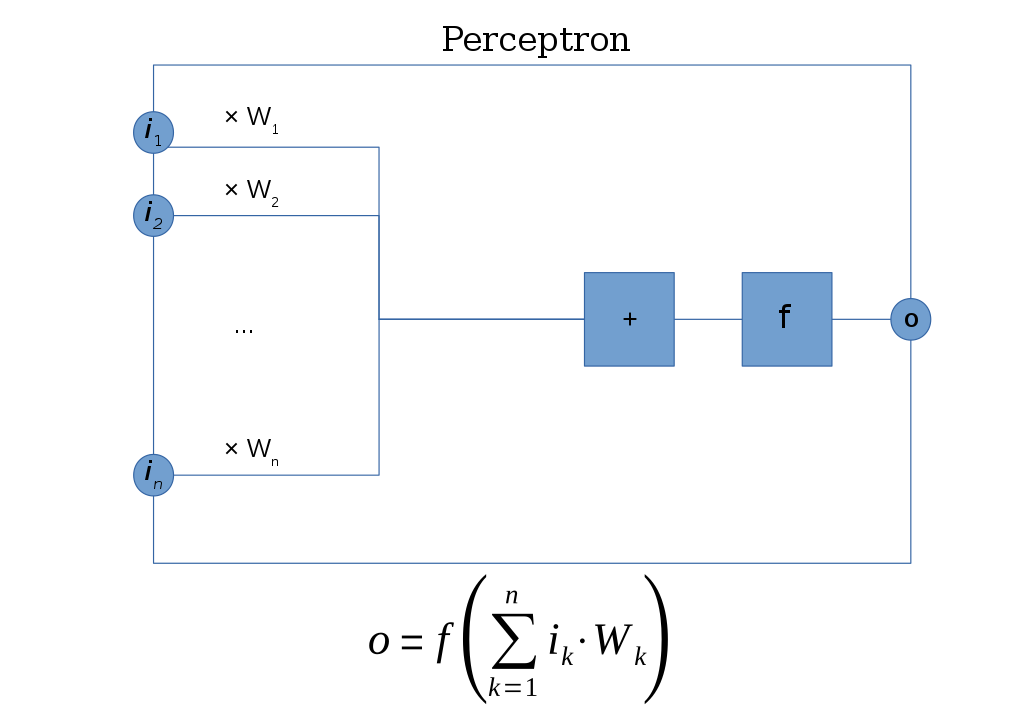
Dans un premier temps, chaque entrée est multipliée avec les poids correspondants. Une somme totale est réalisée permettant d’obtenir une somme pondérée. Par la suite, la fonction d’activation est appliquée afin d’indiquer si la somme pondérée est positive ou négative ce qui induit ensuite le résultat donné en sortie. Techniquement, à l’élaboration de ce type d’IA, les poids sont donnés au hasard au début et ajustés vis-à-vis du résultat obtenu. Les poids sont légèrement modifiés jusqu’à ce qu’il arrive à donner les bonnes réponses. Une fois qu’un nombre suffisant de réponses justes est apporté par le système, on dit qu’il converge. Il est considéré au meilleur de ses capacités. Seulement voilà, en termes de détection d’image, le Perceptron est loin d’être suffisant. Il faut donc trouver d’autres alternatives qui arriveront bien plus tard, à la fin des années 1970 et le début des années 1980 avec l’avènement de la vision par ordinateur. Plusieurs chercheurs se penchent sur la question. D’abord David Marr, un neuroscientifique Britannique qui donne à ses étudiants de travailler sur la problématique de la vision par ordinateur en 1970, un sujet dont il est persuadé qu’il sera réglé en six mois, grand max ! Cinquante ans plus tard, le sujet reste d’actualité ! D’autres scientifiques tels que David G.Lowe ou encore le français Yann Le Cun ainsi que les Américains Paul Viola et Michael Jones participent à différentes échelles à préciser les contours des objets, à détecter des éléments dans une scène ou encore à apporter un plus grand degré de précision. Cependant, malgré des avancées significatives, le niveau d’analyse d’images reste assez mauvais dans les années 2000, le taux de détection se situant péniblement entre 70 % et 80 % en moyenne entre 2009 et 2012. Et c’est précisément là qu’intervient le deep learning.
Plongée au cœur des réseaux de neurones
Les évolutions technologiques successives de ces dernières années participent à l’essor de l’IA et notamment au Deep Learning qui s’envole dès les années 2010 grâce à quatre facteurs déterminants :
Depuis le Perceptron, les avancées en machine learning ont permis la création de réseaux de neurones artificiels multicouches ;
- Les algorithmes d’analyse discriminante et apprenants sont devenus plus performants ;
- La puissance de calcul des machines avec notamment l’apparition des premières cartes graphiques développées par Nvidia offre désormais la possibilité de traiter massivement les données ;
- L’essor de bases de données qualifiées ouvertes et libres d’accès telles qu’ImageNet a apporté la matière première nécessaire pour entraîner efficacement les systèmes d’IA complexes.
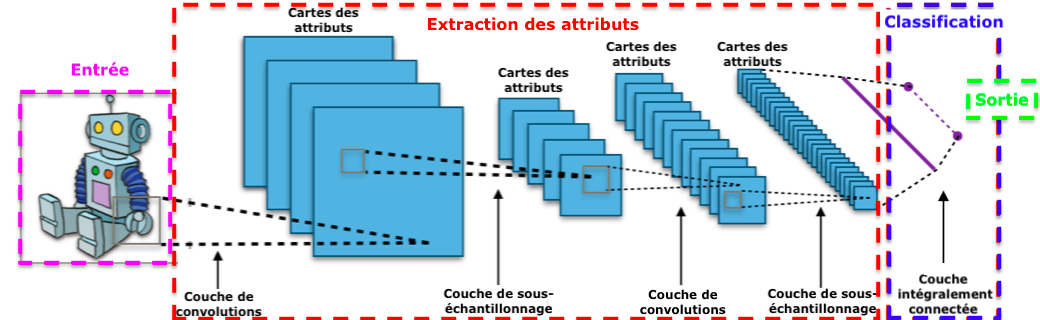
Jusqu’à présent délaissé, le deep learning prend son envol et, avec lui, naît les réseaux de neurones. À la différence du Perceptron qui n’avait qu’une couche composée d’entrées et d’une sortie, ceux-ci multiplient les couches sur le même principe. Cet aspect multicouche permet d’élaborer des architectures de réseaux de neurones complexes, chacune des couches le composant, recevant et interprétant les informations de la couche précédente en effectuant différentes opérations mathématiques. Mieux ! À chaque étape une activation se produit, les « mauvaises » réponses sont supprimées et renvoyées vers les niveaux en amont afin d’ajuster le modèle mathématique. Ces phases masquées permettent au programme de réorganiser les informations en blocs plus complexes jusqu’à arriver à la réponse finale. D’où la notion d’auto-apprentissage. Son fonctionnement n’est en rien comparable au réseau de neurones humains, les chercheurs ne s’étant pas inspirés du cerveau humain lors de son élaboration. Plus il y a de neurones dans un réseau, plus il est profond, mais son architecture reste la même, il ne la change pas contrairement au cerveau humain ou celle-ci est mouvante. Les réseaux de neurones artificiels sont faits pour effectuer une ou plusieurs tâches définies de manière ultra précise, c’est tout ! Toute la difficulté actuellement réside dans le fait d’éviter les biais de traitement en apportant des bases de données qualifiées et équilibrées pour les entraîner ainsi que leur explicabilité. Les réseaux de neurones peuvent posséder plusieurs couches masquées et suivre leur raisonnement pour aboutir à un résultat n’est pas toujours facilement explicable bien que des scientifiques se soient penchés sur la question et arrivent désormais à expliquer, dans les grandes lignes, leur résultat. Des outils comme LIME permettent d’apporter des éléments de réponse sur comment le système a abouti à ce résultat. Un sujet passionnant qui ne cesse de s’améliorer au fil du temps, l’intelligence artificielle touchant l’ensemble de la société, de la voiture autonome aux mails en passant par le secteur médical et l’industrie.










{kind=link}